Firefox Sandbox Vulnerability Research: Introduction and Environment Setup
Intro
An aspect of vulnerability research that can be challenging is setting up a research environment. In particular, if you want to research attack surface that hasn’t received a lot of prior public research, just figuring out what you need to do to reach the point where you can begin hunting for vulnerabilities may be overwhelming. This was my experience when I decided I wanted to perform vulnerability research on a particular layer of Firefox’s sandbox.
Specifically, I wanted to find vulnerabilities in Firefox’s C++ Inter-Process Communication (IPC) layer. There are several different IPC layers in Firefox that could be interesting to research. The four IPC layers are IPDL (which is the C++ layer), Shared Memory, JSActors and Message Manager. Mozilla’s excellent “Attack & Defense” blog series on Firefox internals features a whole post that describes how to get started performing vulnerability research on some of these layers:
However, the IPDL/C++ IPC layer, which is the layer that I wanted to look at, seemed not to have received much public research. This made it an exciting target because I could potentially help contribute some public research to aid other researchers in getting started. It also meant that I might have less competition than attack surface which had lots of public research conducted on it. However, the lack of public information on how to get started also posed a significant challenge. When attacking a piece of software as complex as a browser, there’s a lot of architecture you need to understand in order to do anything meaningful.
My goals for this blog post are to help demystify the process of setting up a very basic environment to perform vulnerability research on Firefox’s Inter-Process-communication Protocol Definition Language (IPDL) IPC layer, and to explain why this is an interesting target for vulnerability researchers. In an effort to make this post accessible, I’ll assume no prior knowledge of sandboxing technology, IPC, or Firefox’s architecture. I’ll walk through these topics and explain the process for getting a barebones research environment set up. This post won’t contain groundbreaking new research, but it will contain a guide on how to get started doing your own research.
The first sections of this post will explain the basics of sandboxing, IPC, and why they’re of interest to vulnerability researchers. If you’re already comfortable with these topics, you may want to skip directly to the section on how to set up an environment to test IPDL/C++ IPC calls.
Disclaimer: I am in no way an expert on any of this. I’m sharing my approach because there’s so little information out there on how to get started with manually auditing this attack surface, but I’m sure the approach detailed in this post is very far from optimal. If you know of better approaches than this one, please share them! I would love nothing more than to be corrected so that more useful information can be available to other researchers.
Additionally, I’d like to extend a thank-you to the Attack & Defense folks at chat.mozilla.org, who kindly took the time to provide some direction for me while I was trying to get an initial environment set up. Without their help, I imagine I’d have been stuck for much longer, if I ever figured it out at all.
What is sandboxing and why is it interesting to vulnerability researchers?
If you’re not familiar with sandboxing, let’s begin by examining what software exploitation looked like 15-20 years ago, before the advent of sandboxing. At that time, if a process contained a vulnerability that an attacker exploited, the attacker could immediately access other resources on the victim’s host (e.g. all of their files). To illustrate this, let’s have a look at some beautifully rendered diagrams.
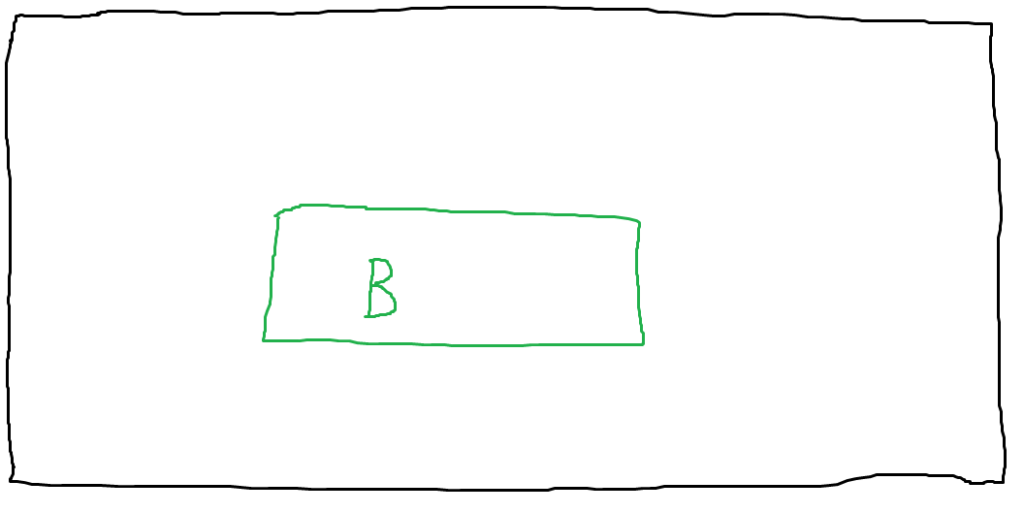 In this first visually arresting diagram, the outer rectangle represents everything available on the victim’s computer — files, running processes, etc. The inner green rectangle represents a running process. In this case, I’ve labeled it with a “B” for “browser”, but this concept could be applied to other software as well.
In this first visually arresting diagram, the outer rectangle represents everything available on the victim’s computer — files, running processes, etc. The inner green rectangle represents a running process. In this case, I’ve labeled it with a “B” for “browser”, but this concept could be applied to other software as well.
Note that there is no boundary between this process and anything else on the host. Should an attacker compromise the browser process, they would still be constrained to the privileges with which the process is running, but there’s otherwise nothing preventing them from reading specific files on the system or performing other malicious actions. Let’s illustrate that.
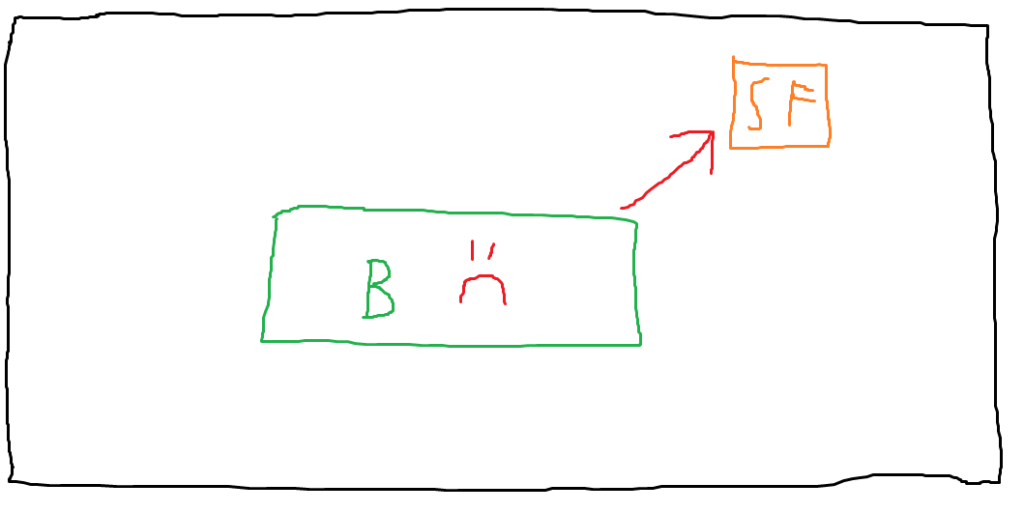
I’ve labeled the browser process with a frowny face to show that it’s now compromised. Let’s assume the victim user has a sensitive file on their host (which I’ve represented with the label “SF”). The compromised browser could directly access this file, assuming that special permissions aren’t required to read it. This is a problem because defenders need to hope that they’ve secured each process well enough to prevent any vulnerabilities from existing. Should an attacker find an exploitable vulnerability, it’s game over. (This simplifies a bit because in the real world, there are often exploit mitigations that may require exploitation of multiple discrete bugs to actually fully compromise a process, but here we’re assuming an attacker has reached the point where they’ve achieved arbitrary code execution or file read).
It isn’t realistic to expect to just write completely secure code. It’s even less realistic when we’re dealing with very complex software like browsers, which present a lot of attack surface. One approach to improve security is to continue implementing more exploit mitigations that will hopefully render existing vulnerabilities unexploitable. While there’s plenty of merit to this strategy, it’s not foolproof. Even today, with the wide variety of exploit mitigations in use, attackers still achieve successful exploitation. It’d be nice if, in addition to the mitigations, there were another layer of protection attackers needed to bypass after exploiting a process.
Enter sandboxing. Let’s use another great diagram to see how sandboxing adds another layer of security.
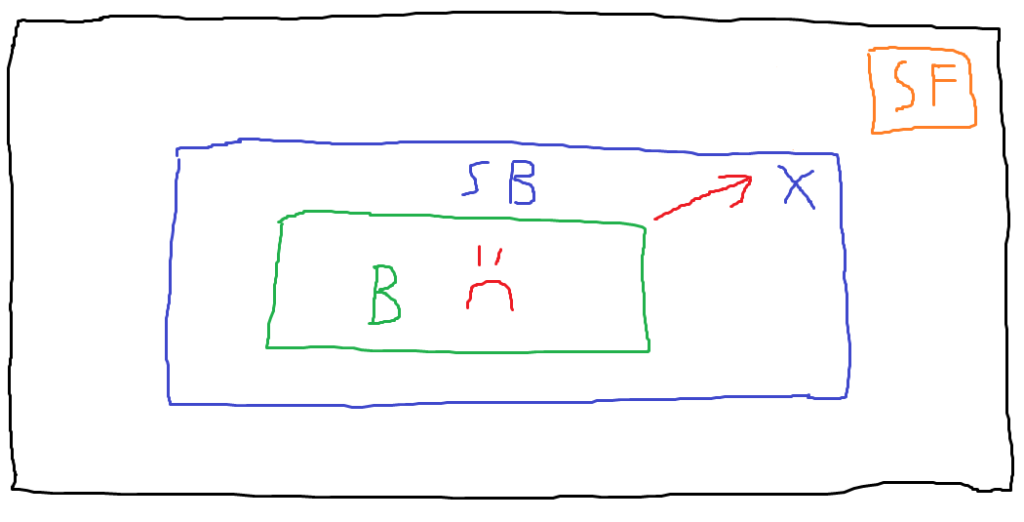
Note that there’s now a boundary between the browser process and the sensitive file. This boundary is the sandbox. There are lots of sandbox implementations out there, and we’ll discuss Firefox’s later on, but the general idea of a sandbox is to restrict what a process is allowed to do or access. For example, if a process has no need to access anything on the filesystem, a sandbox could disallow any syscalls related to reading or writing files. In the breathtaking diagram above, the browser process is still compromised, but when the attacker attempts to leverage it to read the user’s sensitive file, the sandbox blocks their attempt.
If we take this example to an extreme and assume that the sandbox properly restricts every single unnecessary operation, then the sandbox in some ways renders exploitation of the browser process unhelpful to the attacker. If the attacker exploited this process in order to read that sensitive file, but the sandbox prevents them from doing so, they haven’t really achieved anything. This is once again a bit oversimplified, since there might still be something valuable in the compromised process itself that an attacker could want, but the general idea is that sandboxing is intended to limit the impact of a process being compromised, introducing another hurdle for an attacker to overcome. The cost of exploitation has increased for an attacker — they now need to invest the effort of exploiting the sandboxed process, but they also need to identify a vulnerability in the sandbox that allows access to resources outside of the sandbox. This ability to bypass the constraints enforced by the sandbox is commonly referred to as a sandbox escape.
Therefore, sandboxes are interesting attack surface to vulnerability researchers because sandbox escapes are often a necessary part of a full exploit chain. Mozilla has a wiki article on sandbox security that offers some more context on how sandboxes can be escaped: https://wiki.mozilla.org/Security/Sandbox/IPCguide
In addition to the sandbox escape methods detailed in that wiki article (kernel exploitation or IPC exploitation/abuse), another method is to simply exploit a component that is not sandboxed. This sounds like a cop-out solution to bypassing sandboxing, but happens in the real world. For example, the following Google Project Zero writeup describes an exploit for iOS that targeted some processing that took place outside of the BlastDoor sandbox: https://googleprojectzero.blogspot.com/2021/12/a-deep-dive-into-nso-zero-click.html
How is sandboxing implemented in Firefox?
Now that we have a general understanding of sandboxing, let’s see how it’s implemented in Firefox. Mozilla already offers some great documentation on this topic, so I’m largely going to avoid reproducing that here. An essential read is the following Attack & Defense blog post on fuzzing Firefox’s IPC layer: https://blog.mozilla.org/attack-and-defense/2021/01/27/effectively-fuzzing-the-ipc-layer-in-firefox/
The above post includes a diagram (of slightly higher quality than my own) that shows how the sandbox in Firefox acts as a trust boundary between processes. I will assume that you have read the above post and just briefly summarize the key points:
-Firefox is not composed of a single monolithic process. Instead, each site receives its own process which we will refer to as the content process (aka the child process).
-The content processes are sandboxed. This is because a content process is what a victim user would be using if they, for example, browsed to an attacker-controlled site that exploited a bug in the browser. This could lead to compromise of the content process, so it’s important for them to be sandboxed.
-A process exists that is not sandboxed and governs the content processes. This process is called the parent process (aka the main process or the chrome process; confusingly, the name “chrome” in this case has nothing to do with Google’s Chrome browser, and is just another name for the parent process).
-IPC is the mechanism through which messages from the unprivileged content processes are sent to the parent process. When a content process needs to do something that it can’t do within the sandbox, but is implemented by Firefox because it’s an expected action, it will issue an IPC call to the parent process so that the action can be performed by the parent on the content process’s behalf.
-There are multiple IPC layers. For the purposes of this blog post, the layer we’re interested in is the IPDL layer (which involves C++ IPC calls). There are three other IPC layers: Message Manager, JSActors, and Shared Memory. The Message Manager layer and JSActors layer are implemented in JavaScript and may be another popular target for sandbox escapes. We’ll examine why I chose to examine the IPDL layer in the next section.
You may find this documentation on Firefox’s process model helpful:
https://firefox-source-docs.mozilla.org/dom/ipc/process_model.html
Why is the C++ IPC layer interesting? What might a sandbox escape look like here?
So, given that there are multiple IPC layers, and some of them have more public documentation for vulnerability researchers, why are we interested in the IPDL/C++ layer specifically? I had a couple of reasons I wanted to look at this layer in particular:
-Auditing C++, and identifying vulnerabilities common to it such as memory corruption, is of interest to me. This is personal preference. Someone who hates auditing C++ code might want to take a look at the JavaScript IPC layers instead.
-The lack of much public information on how to get started with researching this layer meant that setting up a research environment posed an exciting challenge. As mentioned earlier, it also meant that I might be competing with fewer researchers on this attack surface than I would be on something that’s really well documented and easy to get started on.
Now that we have an idea of Firefox’s sandbox architecture and process model, let’s look at a couple of last diagrams to understand the kinds of bugs we ultimately want to be able to find.
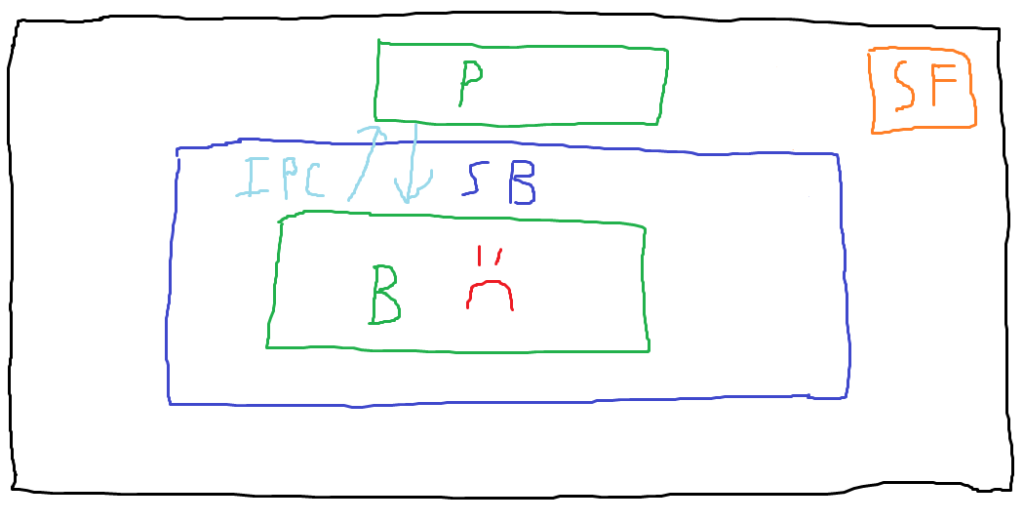
In this diagram, note that we’ve added an unsandboxed parent process (labeled with “P”), and that legitimate IPC messages are being exchanged between the sandboxed browser process (AKA the content process) and the parent process. This depicts normal behavior. In a final blaze of artistic glory, let’s examine what exploitation might look like in this scenario.
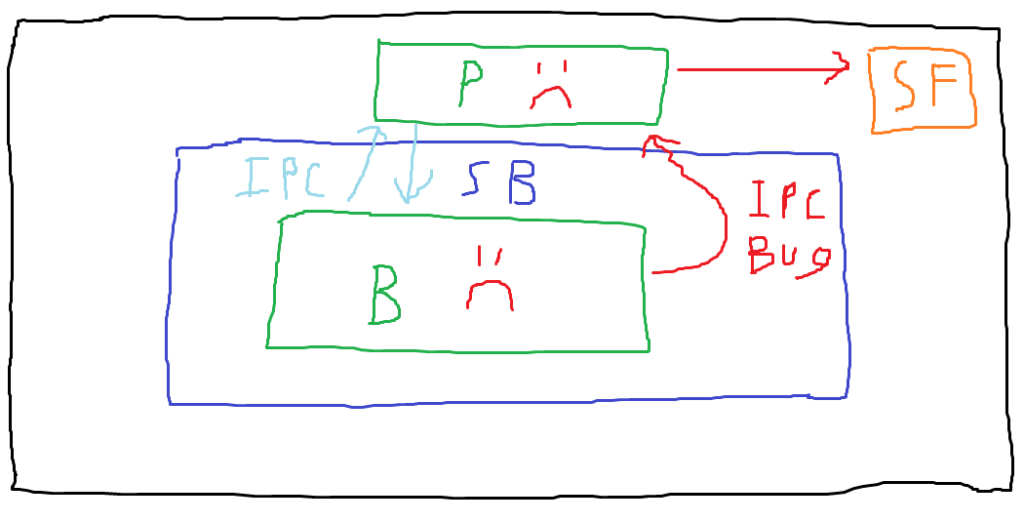
In the attack scenario depicted, the attacker has compromised the content process and then made a malicious IPC call to the parent process. We assume that the call the attacker makes exploits a bug in the handling of the IPC call, compromising the parent process. Now that the attacker is no longer constrained by the sandbox, they can use the compromised parent process to access the sensitive file on the host. These IPC vulnerabilities that allow compromising the parent process (or getting it to return something to the content process that it shouldn’t) are the bugs we’re interested in.
At this point, we understand the absolute basics of Firefox’s sandbox implementation and we’ve selected the attack surface we want to look at. Time to put some thought into the kind of environment we want for our research.
The end goal
Ultimately, we want to be able to make arbitrary IPC calls (with arbitrary arguments) from the content process to the parent process. We’ll want to be able to debug those processes so we can see what’s happening when those calls are sent and received. This is necessary because during manual auditing of the IPC C++ code, if we identify an interesting call and want to see if we can confirm a vulnerability, we’ll need to be able to perform dynamic testing at some point. Purely static analysis is hard!
The plan
Because the IPC calls we want to look at are triggered from C++, we’ll need to understand how to make them. Consider that the attack scenario we want to simulate is that the content process has been compromised by an attacker, but they have not yet escaped the sandbox. They now want to exploit a bug in an IPC call to achieve a sandbox escape. An attacker with arbitrary code execution within the content process could probably invoke these C++ IPC calls directly. However, unless we want to either identify and exploit a zero-day vulnerability, use an outdated Firefox version and exploit an existing bug, or artificially patch one into Firefox and then write an entire exploit for it, we don’t have that same kind of access.
One place in the content process where we can easily run code is the JavaScript console. Wouldn’t it be nice if we could just make IPC calls directly from that? The Chrome browser does implement something like this with MojoJS bindings, which essentially expose a subset of Chrome’s IPC calls to JavaScript. You can learn more about MojoJS bindings here: https://chromium.googlesource.com/chromium/src/+/HEAD/mojo/public/js/README.md
However, as far as I’m aware, Firefox has no such analog. Even in Chrome, it’s my understanding that the MojoJS bindings don’t expose all IPC calls, so if you want to reach ones that aren’t exposed by those bindings, you need to come up with your own solution, just like we need to in Firefox. So, if those bindings don’t exist, how can we expose an IPC call to the JavaScript console?
With some minor information on a proof of concept provided for a bug that, as of this writing, is still private (CVE-2024-2605, https://bugzilla.mozilla.org/show_bug.cgi?id=1872920; credit to the bug reporter for the approach we’ll be following in this post), the approach I landed on was to simply patch the C++ code associated with a function in the JavaScript console. This is code that’s associated with the content process. We’ll add code to a function that will allow us to invoke an IPC call at will from the JavaScript console. This post will only cover making a single basic IPC call, but if you needed to make multiple IPC calls in a specific order to be able to successfully make the call you’re interested in, you could certainly add more than one.
Environment Setup
At long last, we’ve got a plan and can begin with setup. This post will cover setting up an environment on Linux. For reference, I performed these steps on a VM running Ubuntu 22.04.4 LTS.
Step 1: Building Firefox
We’ll want to build Firefox from source, and eventually build a version containing our patch. Firefox has very clear documentation on the process for building from source here: https://firefox-source-docs.mozilla.org/setup/linux_build.html
The only additional step that I strongly recommend here is to use the “sccache” build option, which is documented here: https://firefox-source-docs.mozilla.org/setup/configuring_build_options.html#sccache
Building Firefox from source takes a long time (on my VM, the build time was probably somewhere in the range of 1-1.5 hours). However, the sccache build option will help dramatically speed up subsequent builds. With sccache, when making only the changes necessary for my patch and rebuilding, builds took around a minute or less.
Aside from adding the sccache build option, the Firefox documentation should be sufficient to get an initial build of Firefox from the source.
Step 2: Determining the IPC call we want to make
Before we start developing our patch, we’ll want to select an IPC call to make. Since at this point we’re not trying to find vulnerabilities, just set up an environment, we’ll look for a very simple call that stands on its own (that is, it doesn’t require some specific sequence of earlier IPC calls to work). To select an IPC call, I decided to look at the calls defined in ContentParent.cpp, which can be accessed here:
https://searchfox.org/mozilla-central/source/dom/ipc/ContentParent.cpp
We’re specifically interested in functions with “Recv” in the name, as these should have a corresponding function on the content process side with “Send” in the name. There are probably lots of good candidates, but the one I settled on was mozilla::ipc::IPCResult ContentParent::RecvAddGeolocationListener(const bool& aHighAccuracy) , which can be found here (as of this writing; note that all line numbering provided in this post is subject to change):
https://searchfox.org/mozilla-central/source/dom/ipc/ContentParent.cpp#5039
mozilla::ipc::IPCResult ContentParent::RecvAddGeolocationListener(
const bool& aHighAccuracy) {
// To ensure no geolocation updates are skipped, we always force the
// creation of a new listener.
RecvRemoveGeolocationListener();
mGeolocationWatchID = AddGeolocationListener(this, this, aHighAccuracy);
return IPC_OK();
}
This function looks promising. It takes only a single parameter, which is just a boolean. Now that we have a function picked out, let’s see if we can find the corresponding send function on the content process side of things. By searching the codebase for “AddGeolocationListener”, we can find the following code block in Geolocation.cpp that invokes the “Send” version of this IPC call:
https://searchfox.org/mozilla-central/source/dom/geolocation/Geolocation.cpp#633
if (XRE_IsContentProcess()) {
ContentChild* cpc = ContentChild::GetSingleton();
cpc->SendAddGeolocationListener(HighAccuracyRequested());
return NS_OK;
}
Great! We now have an IPC call we want to invoke and we know how it should look on the content process side of things and the parent process side. Let’s start figuring out how our patch should look.
Step 3: Writing our patch
If we want to patch something associated with the JS console, we’ll want to take a look at its code:
You could probably take this approach with lots of functions, but we’ll target the console.time() function, which appears here (again, credit to the reporter of CVE-2024-2605 for this approach):
Specifically, we’ll plan to add our patch right after the following line:
aTimerLabel = label;
All we want our patch to do is make the SendAddGeolocationListener() IPC call. First, we’ll need to add some preprocessor directives to include some additional headers so that we can access the function we want to call. After some experimentation, I found that the patch can work with these include statements added to the top of the Console.cpp file:
#include "../../obj-x86_64-pc-linux-gnu/ipc/ipdl/_ipdlheaders/mozilla/dom/PContentChild.h"
#include "../ipc/ContentChild.h"
#include "../geolocation/Geolocation.h"
Now we can add our patch to the Console::StartTimer() function referenced earlier. Here’s the patched code:
aTimerLabel = label;
// Our custom code, an if() block, appears here
// we can access by calling console.time("INVOKE_IPC")
if (aTimerLabel.EqualsASCII("INVOKE_IPC")) {
ContentChild* cpc = ContentChild::GetSingleton();
bool success = cpc->SendAddGeolocationListener(false);
return eTimerJSException;
}
This is essentially just a slightly minimized version of the code we looked at in Geolocation.cpp. Here are a few things to note:
-Our patched block will only trigger when console.time() is called with a specific string. In this case, we’re using the string “INVOKE_IPC”.
-In the call SendAddGeolocationListener(false), for simplicity, we’re using a boolean directly instead of invoking HighAccuracyRequested().
-We’re returning an eTimerJSException mostly because it’ll provide some feedback in the console when our patched block is completed.
Step 4: Building Firefox again
Now that we’ve got our patch implemented, we just want to rebuild Firefox. Hopefully you used sccache!
Step 5: Making our IPC call
With Firefox rebuilt with our patch, now we just need to test it and verify that an IPC call is being made from the content process to the parent process. First, let’s go ahead and launch our patched Firefox. Then, open a second tab and navigate to the about:processes page. This page will provide the PID of the parent process, which we’ll need for debugging purposes.
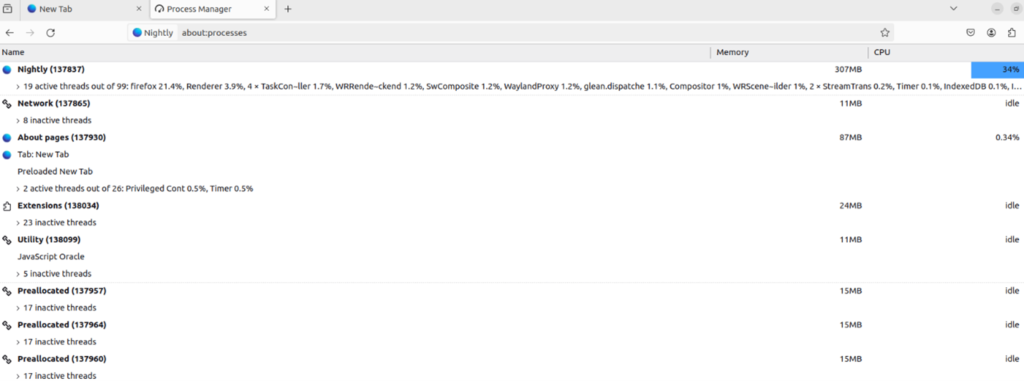
In my case, the parent process, which is the first process in the list, has the PID 137837. You’ll need to find the PID on your system. We’re going to use GDB to attach to this. I use GDB GEF (https://github.com/hugsy/gef), but its features aren’t necessary for this specific process.
First, launch GDB. Then, within GDB, run:
attach <PID goes here>
On my system, it can take several minutes for the debugger to complete attaching and present a GDB prompt. While attaching, the browser process should freeze. Once the GDB prompt is presented, we’ll want to set a breakpoint on the mozilla::dom::ContentParent::RecvAddGeolocationListener(bool const&) function, since that’s the one that gets used on the parent process side of things when the corresponding IPC call is made by the content process.
break mozilla::dom::ContentParent::RecvAddGeolocationListener(bool const&)
After setting the breakpoint, we can run the “c” command to continue execution. Next, navigate back to the first browser tab that is not on the about:processes page. This should just be a blank tab. Go ahead and open the JavaScript console and run the following command:
console.time("INVOKE_IPC")
When you run this command, the breakpoint should be triggered in GDB, demonstrating that we’ve successfully made an IPC call from the content process to the parent process!

Note that you can continue execution gracefully. With that, we’ve managed to write a patch that allows making an IPC call via JavaScript, and we’re able to debug the call in the parent process.
Limitations
At this point, we’ve achieved our goal. However, I think it’s worth acknowledging that this is almost certainly not the optimal solution. There’s probably a fancy way of making this more flexible, with all IPC calls available via JS and without the requirement of rebuilding Firefox every time you want to make a change. I have no doubt that plenty of people out there have better approaches to this. I have at least one other technique on my radar to try in the future. However, as someone with very limited development skills, this approach is sufficient for me, at least for now. If you have a more elegant solution, please share it so that I and other researchers can learn from it! Until then, this inelegant solution is a lot better than having no solution at all.
Conclusion and next steps
In this post, we covered how sandboxes work generally and examined Firefox’s sandbox implementation and process model. We identified an approach to make C++ IPC calls from the content process to the parent process, determined a simple IPC call to make for our proof of concept, and patched Firefox’s content process code to enable making a C++ IPC call from JavaScript. We also made use of a debugger to ensure our call was being made successfully.
At this point, the next step would be to begin auditing the C++ IPC code in Firefox. Upon identifying something potentially vulnerable, the ability to make this call from JavaScript could be patched into Firefox, as we did with our proof of concept. This will enable the ability to dynamically test the IPC call for vulnerabilities rather than relying on static analysis alone. I hope this post was helpful to others who aspire to perform vulnerability research on the Firefox sandbox.
Written by: Josiah Pierce