A Brief Introduction to Semgrep (Part 2)
Introduction
Semgrep is an impressive modern static analysis tool that simplifies hunting for complex patterns in code. One interesting use for this tool is in identifying potential vulnerabilities. This blog post will serve as a quick overview of a few of Semgrep’s helpful features for vulnerability hunting. See part 1 for a high-level overview of Semgrep and how to use it.
Note that these examples merely scratch the surface of Semgrep’s capabilities and are only intended to whet your appetite. If you’d like to learn more, further learning resources are provided at the end of the post.
Advantages of Semgrep
Many of us have probably spent time using standard grep with regular expressions to hunt around for dangerous function calls and other issues. If you’re already comfortable with grep, why use Semgrep instead?
Semgrep implements an array of quality-of-life features to make writing (and reading) patterns easier and faster than equivalent regular expressions with grep. Some of those features include:
- Semgrep doesn’t match on comments (reducing the volume of output it produces), and is aware of code structure, meaning it can match on code that spans multiple lines
- Semgrep allows easy variable tracking throughout the code
- Semgrep understands language semantics and can match on equivalent expressions. For example, if you want to match on a particular set of arguments to a function, Semgrep is aware of whether the argument order matters. If the order of the arguments is irrelevant, it’ll match on any order, even if it’s not the order you wrote in your Semgrep pattern
- Semgrep can be quickly installed via pip, Docker or brew; it can also be used in a browser-based editor (as seen later in this post)
- Semgrep offers free community-created rulesets for identifying specific issues in various languages
Some of this behavior can be seen in the following examples.
Example: use after free vulnerability
As an initial outing with Semgrep, let’s try identifying a basic use after free vulnerability in some C code. Use after free is an interesting bug choice, because this type of vulnerability involves multiple function calls and is likely to be spread across multiple lines. To further complicate matters, the vulnerable lines may be located far away from one another, meaning a search for them can’t expect them to appear contiguously in the code.
To get started, we can use Semgrep’s browser-based editor, available here: https://semgrep.dev/editor/
(There’s also a local version, but the browser-based version is more than enough for our purposes.)
The editor provides a choice of programming languages to parse, a text box for writing the Semgrep pattern that is used to search through your code, and a text box for the test code itself.
Next, let’s choose some helpful code that provides an example of a use after free vulnerability, which can be found here: https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/use_after_free/
The code is reproduced below, with some of my own commented annotation numbers:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
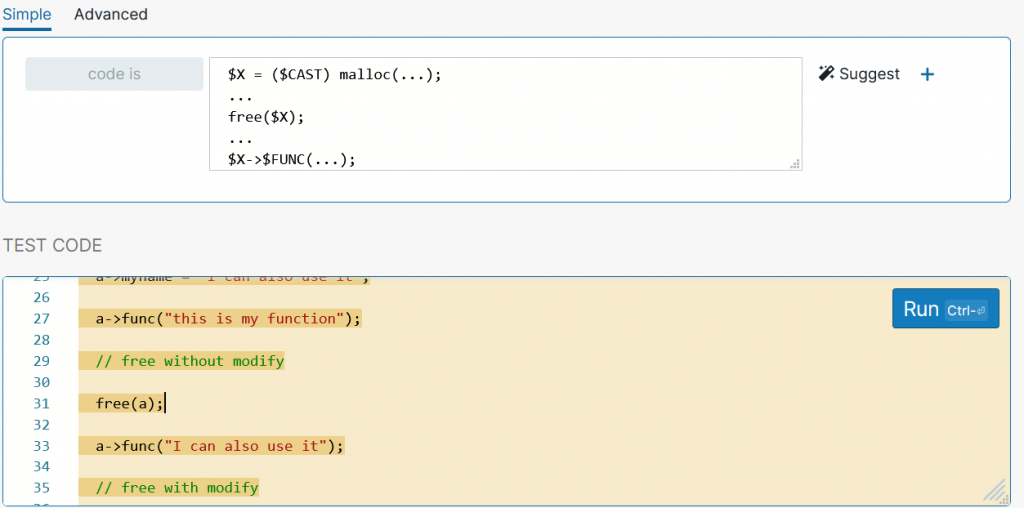
#include <stdio.h> #include <stdlib.h> typedef struct name { char *myname; void (*func)(char *str); } NAME; void myprint(char *str) { printf("%s\n", str); } void printmyname() { printf("call print my name\n"); } int main() { NAME *a; a = (NAME *)malloc(sizeof(struct name)); // [1] a->func = myprint; a->myname = "I can also use it"; a->func("this is my function"); // free without modify free(a); // [2] a->func("I can also use it"); // [3] // free with modify a->func = printmyname; a->func("this is my function"); // set NULL a = NULL; printf("this pogram will crash...\n"); a->func("can not be printed..."); } |
[1] – The vulnerable object is allocated via malloc().
[2] – The vulnerable object is freed. [3] – A function pointer in the vulnerable object is then used, creating the use after free vulnerability.Based on the above annotations, we can begin to consider how to create a Semgrep pattern that will identify code patterns that feature those general steps. To do so, let’s back up a little and learn about a couple of Semgrep features that will be helpful.
Metavariables and ellipses
One particularly useful feature of Semgrep is its “metavariables”, which essentially allow you to match on something without knowing precisely what it’ll look like beforehand. For example, consider the following Semgrep pattern:
$X = 1337
A metavariable in Semgrep is represented with the dollar sign and then some combination of uppercase letters, digits and underscores. (Note that lowercase letters can’t be used with metavariables! This tripped me up initially.)
The Semgrep rule above could match a line like this:
int example = 1337;
The metavariable $X will be assigned to “example” in this case. We can reference that metavariable in a Semgrep rule to look for later occurrences. We’ll see an example of that in a moment, but first let’s learn about one other operator in Semgrep – the ellipses operator.
You can learn about this operator in much more detail using the full Semgrep tutorial and documentation (linked at the bottom of this blog post), but the quick summary is that the ellipses operator is a “skip over this” operator. You can provide ellipses between sections of a Semgrep pattern to indicate that some code may be between the things you want to match on, but that you’re not interested in what it is. It can also be used during function calls to indicate that some parameters might be provided to a function, but you don’t care what those parameters are or how many there are.
Here’s some code to use for an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#include <stdio.h> int add(arg1, arg2) { return arg1 + arg2; } int main() { int example = 1337; int some_other_variable = 42; int result = add(5,example); return 0; } |
In this example, we can combine our knowledge of metavariables and the ellipses operator to identify when an integer with the value 1337 is defined and then later used in the add() function.
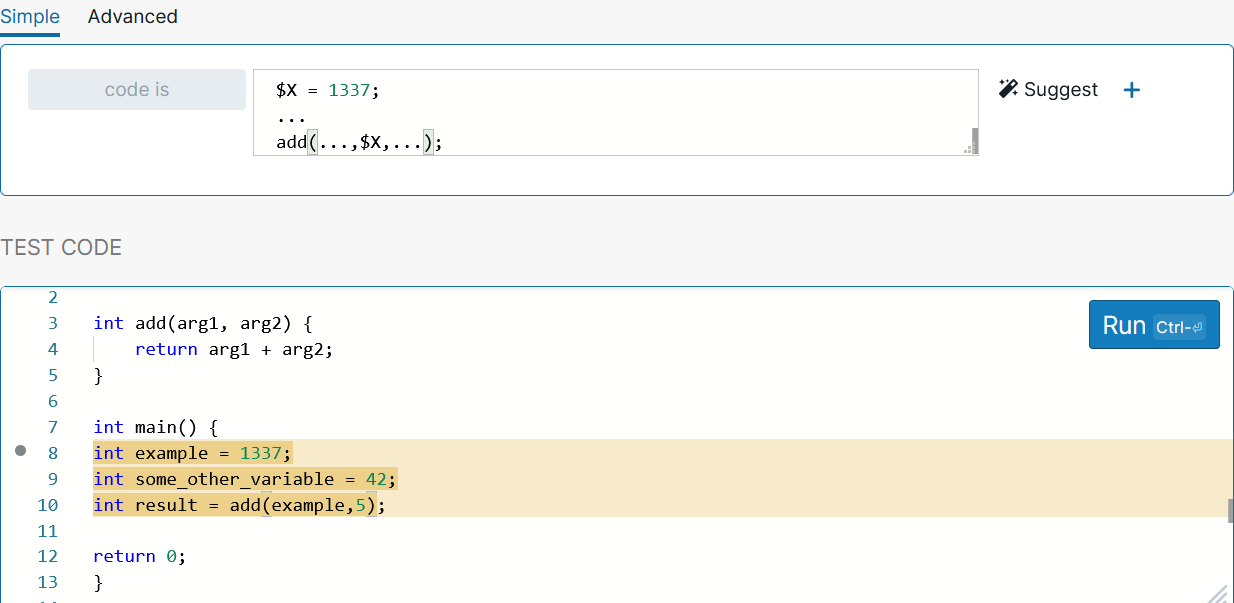
Let’s try this simple Semgrep pattern:
|
1 2 3 |
$X = 1337; ... add(...,$X,...); |
Here, we’re setting $X to be our metavariable that gets assigned the value 1337. In the actual code, that’ll correspond to the “example” variable. We’re then using the ellipses operator to indicate that code may or may not appear between the initial definition of $X and its usage in the add() function. In the case of our example code, there actually is a line of code between the definition and usage.
Finally, we’re looking for any usage of the add() function that contains our metavariable $X as a parameter. The ellipses operators indicate that other arguments could precede or follow $X. This helps account for any order of arguments to add(), so long as $X still appears somewhere.
Running this Semgrep pattern flags the code pattern we’re searching for, as seen in the following screenshot:
Returning to the use after free pattern
With our detour to learn about metavariables and the ellipses operator complete, let’s return to our original goal: we want to write a Semgrep rule that can identify a basic use after free code pattern. We can break the process into steps by considering the earlier annotations and tackling them one at a time.
[1] – The vulnerable object is allocated via malloc().So to start, we’ll want to write a Semgrep rule that can identify calls to malloc(). (In a real scenario, calls to calloc() or other allocation functions would also probably be worth identifying, but for the purposes of this post we’ll just stick with the basic example).
One additional consideration is that we’re going to want to be able to track allocated objects throughout the code. Just finding all the times an object is allocated won’t tell us much; being able to see when an object is allocated and then find out if it’s later freed and used is our goal. To track an object, we can make use of Semgrep’s metavariable functionality we learned about earlier.
To just identify occurrences of that first allocation step, the following pattern should work well:
$X = malloc(...);
Here we’re using a metavariable so we can easily track an allocated object and identify later operations on it. We’re also using the ellipses operator so that we can identify uses of malloc() regardless of the exact format the parameters take; for example, this way our pattern will flag on both malloc(sizeof(something)) and malloc(16) (or any other fixed size).
There’s one small change we’ll want to make. Consider this line in the example code we’re using:
a = (NAME *)malloc(sizeof(struct name));
In the example code, there’s a cast performed directly before the malloc() call to set the pointer to be of the NAME type. If we use our Semgrep pattern exactly as it’s currently written, then this method of calling malloc() will not be flagged.
One solution (which I received from the Semgrep Slack) is to just use a second metavariable to deal with any potential casts used during the malloc() call, like this:
$X = ($CAST) malloc(...);
You may have noticed that now we have the same problem, but in reverse – with this Semgrep pattern, we won’t be able to flag on a call to malloc() without a cast, since our pattern is expecting one. This is a problem we’ll address later on in the post, but for now we’ll just stick with this pattern that expects a cast.
Let’s move on to step 2 in the vulnerable code pattern:
[2] – The vulnerable object is freed.This is much simpler. All we need to do is see if the metavariable we’re tracking is ever passed as an argument to free(). Our only other consideration is that there will likely be code between the lines for allocating the object and for freeing it, so we can use the ellipses operator to deal with that. Here’s our next version of the pattern:
|
1 2 3 |
$X = ($CAST) malloc(...); ... free($X); |
There’s one final step to address in the vulnerable code pattern:
[3] – A function pointer in the vulnerable object is then used, creating the use after free vulnerability.No new techniques are required to complete this step. Since we’re primarily interested in finding function pointers being called, it makes sense to write a pattern that checks to see whether the object we’ve been tracking ever has its function pointer referenced after the object has been freed. Here’s the full Semgrep rule:
|
1 2 3 4 5 |
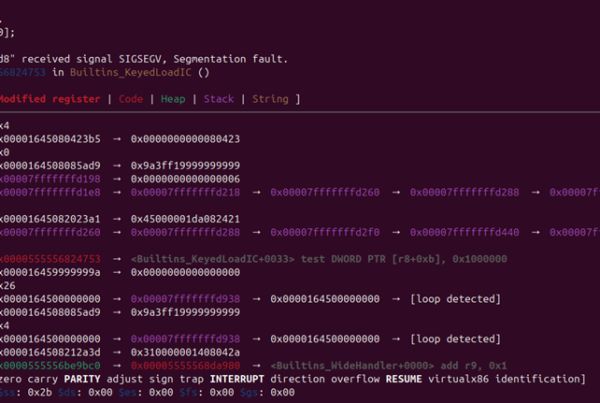
$X = ($CAST) malloc(...); ... free($X); ... $X->$FUNC(...); |
For the purposes of our pattern, it doesn’t really matter what function is being called within $X, so we can use another metavariable for the function name to help make our Semgrep pattern a little more general. Let’s go ahead and give the pattern a spin.
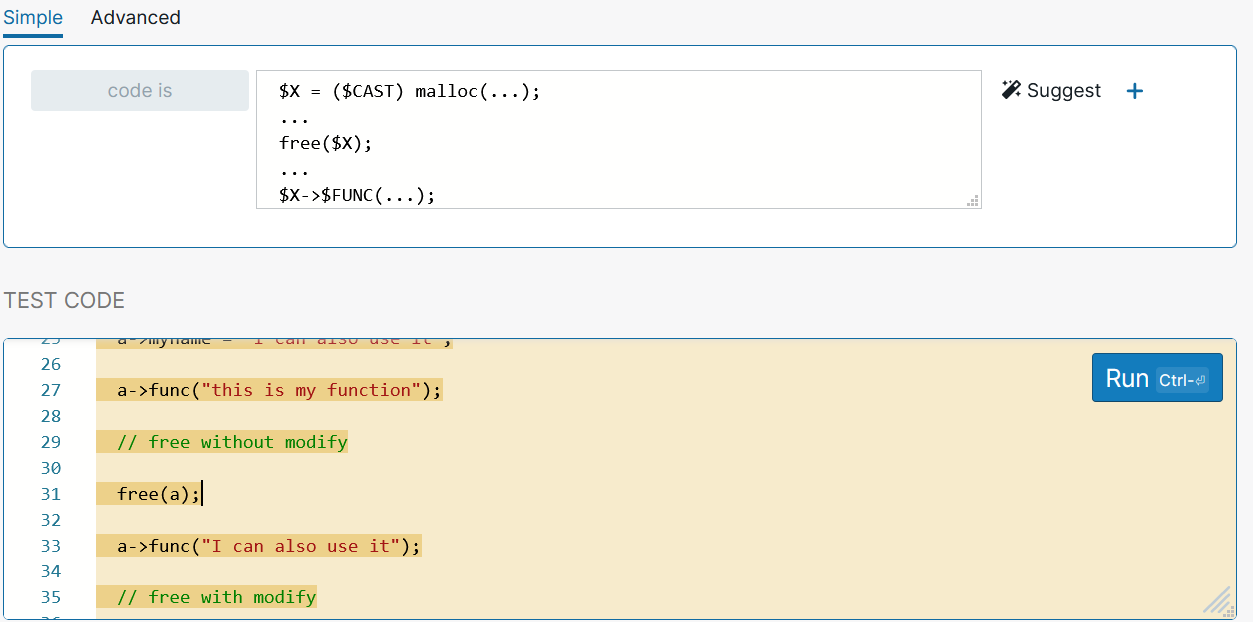
As seen in the screenshot, our pattern has successfully flagged the portion of the code that contains the use after free vulnerability!
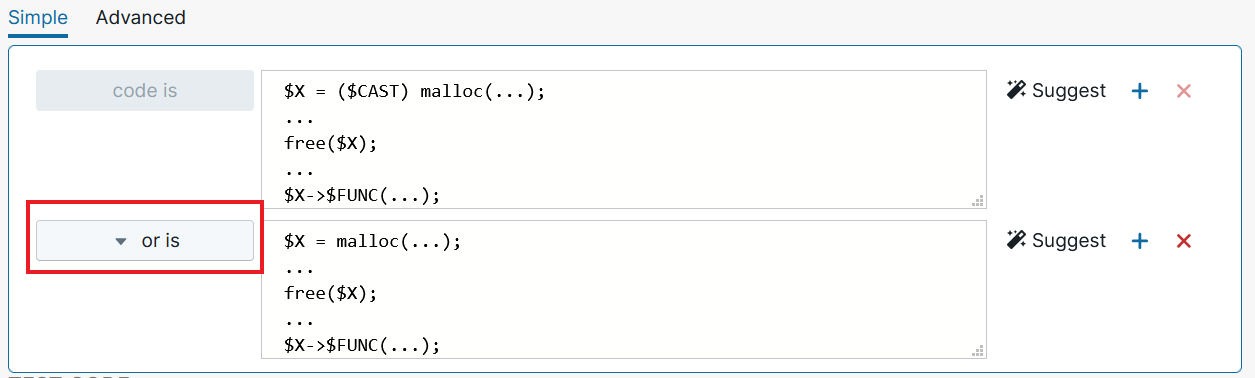
The pattern could still be refined, though. Recall that earlier we wrote our pattern to detect calls to malloc() that are preceded by a cast such as (NAME *). If we’d like to detect both calls to malloc() that contain a cast and calls that don’t, it’s possible to use Semgrep’s “or is” Boolean logic to create multiple patterns to match on. Let’s add a pattern that looks approximately like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$X = ($CAST) malloc(...); ... free($X); ... $X->$FUNC(...); Or is $X = malloc(...); ... free($X); ... $X->$FUNC(...); |
The following screenshot more precisely displays how the “or is” Boolean is used in the Semgrep editor:
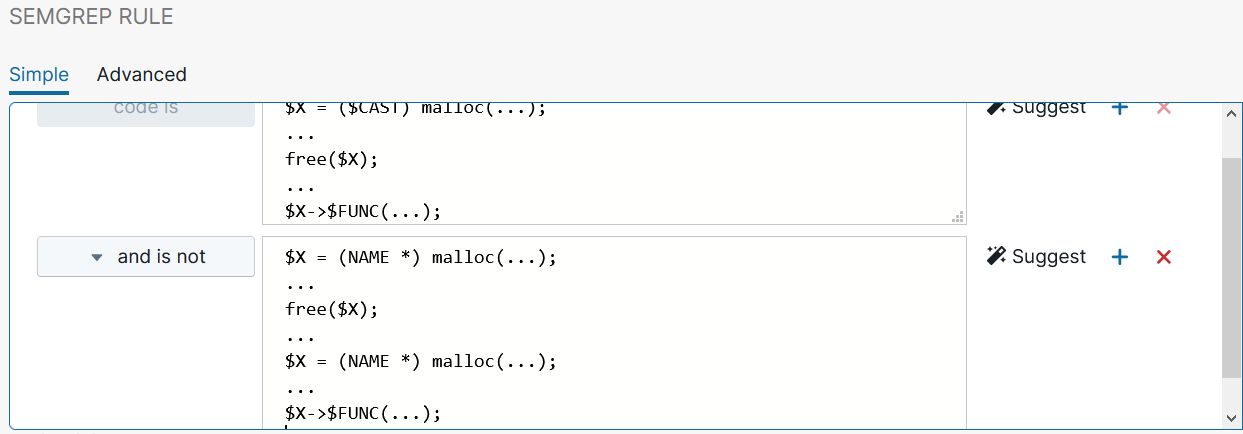
Other Boolean logic operators also exist within Semgrep. For example, an “and is not” operator allows you to specify patterns you don’t want to flag. Perhaps you want to look for a general pattern, but if particular elements are present, you already know the pattern isn’t vulnerable and should be ignored. The “and is not” operator could be used to filter down the false positives.
As an example, when searching for a use after free vulnerability, you may want to flag the pattern we identified previously, but not if the object you’re tracking gets allocated again before being used. Our current pattern just checks to see than an object is allocated, freed, and then used. It doesn’t consider the possibility that the object might be allocated, freed, then allocated again, and then used (which would be perfectly legitimate).
To avoid flagging on that scenario, the following “and is not” block could be added:
|
1 2 3 4 5 6 7 |
$X = (NAME *) malloc(...); ... free($X); ... $X = (NAME *) malloc(...); ... $X->$FUNC(...); |
One advantage of using Semgrep over traditional regular expressions is that Semgrep patterns can closely resemble the code pattern we want to identify. Regular expressions frequently take some effort to visually parse and understand, whereas the Semgrep pattern we leveraged for this example looks like straightforward pseudocode. Additionally, just knowing a few basic Semgrep operators makes it easy to search for a relatively complex code pattern like a use after free.
It’s worth noting that the example vulnerable code is dramatically simplified from what you’re likely to come across in a real codebase. It’s extremely unlikely that you could point this Semgrep pattern at something like the Chromium sandbox and find bugs (though you could always try!). However, the example still provides an opportunity to learn about several of Semgrep’s useful functions and establish a basis for identifying patterns in more realistic code.
Conclusion
Semgrep is a powerful new static analysis tool that looks especially promising for identifying vulnerable code patterns. It features a variety of helpful functionality, including the ability to easily track variables throughout code and to quickly write rules to identify complex patterns. Semgrep rules can visually resemble the code you’re searching for, making them easier to parse than equivalent regular expressions.
Semgrep has a wide array of other capabilities and quality-of-life features. If this post has piqued your interest in the tool, be sure to check out the links in the following section, especially the interactive Semgrep tutorial.
Further Learning
https://r2c.dev/blog/2020/semgrep-stop-grepping-code/ [An overview of many of Semgrep’s features from the tool’s developers]
https://semgrep.dev/learn [An interactive Semgrep tutorial]
https://semgrep.dev/rulesets [A list of existing Semgrep rulesets to try]